
You can remove or replace the variables to ensure independence. Even though discriminant analysis is similar to logistic regression, it is more stable than regression, especially when there are multiple classes involved. If you are classifying the data into two groups, then it is known as Discriminant Function Analysis or DFA. If there are more than two groups, then it is called multiple discriminant analysis or Canonical Varieties Analysis .
Mulitvariate dependence techniques are variants of the general linear model . Data science master course by Digital Vidya is just what you need. It covers all the topics that are applied in data science. Data classification and prediction continues to be a relevant field.
This leads to the framework of regularized discriminant analysis or shrinkage discriminant analysis. Is purely a function of this linear combination of the known observations. Lasso regression is another regularization technique to reduce the complexity of the model. It helps to solve the problems if we have more parameters than samples. It is a predictive analysis algorithm which works on the concept of probability. Logistic regression algorithm works with the categorical variable such as 0 or 1, Yes or No, True or False, Spam or not spam, etc.
All the samples in the data should be independent of each other. Linear Discriminant AnalysisThis line can clearly discriminate between 0s and 1s in the dataset. The objective of LDA is to therefore argue the best line that separates 0s and 1s.
This can make the diagnosis faster and free from errors. You can analyse the influence of each predictor from its coefficients. The function derived above should be statistically significant.
Most of the variables that are used in real-life applications either have a normal distribution or lend themselves to normal approximation. A technique for classifying data, discriminant analysis works with responses to questions posed in the form of variables and other factors that serve as predictors. It is also used to find the contribution of every parameter in dividing the groups. Identifying one or more linear combinations of the variables that have been chosen is how discriminant analysis does its work. We have two classes and we know the within-class density.
If there are two lines of regression and both the lines intersect at a selected point (x’, y’). According to the property, the intersection of the two regression lines is (x`, y`), which is the solution of the equations for both the variables x and y. Standard deviation is the dispersion of mean from a data set by studying the variance’s square root. The regression line reduces the sum of squared differences between observed values and predicted values. Ŷ is known as the predicted value of the dependent variable.
Both LDA and PCA are used as dimensionality reduction techniques, where PCA is first followed by LDA. LDA is much more suitable for multi-class classification tasks compared to PCA. However, PCA is assumed to be an as good performer for a comparatively small sample size.
The prediction is made simply by the use of the Bayes Theorem which estimates the probability of the output given the input. They also make use of the probability of each class and also the data belonging to that class. After the clusters are built, a lot of statisticians/analysts generally use either Discriminant or logistic model as the predictive technique to classify any new observation.
Businesses use discriminant analysis as a tool to assist in gleaning meaning from data sets. This enables enterprises to drive innovative and competitive remedies supporting the consumer experience, customization, advertising, making predictions, and many other common strategic purposes. Not only is it possible to solve classification issues using discriminant analysis.
Important Properties of Regression Line
Commonly used checks of goodness of fit include the R-squared, analyses of the pattern of residuals and hypothesis testing. Statistical significance can be checked by an F-test of the overall fit, followed by t-tests of individual parameters. Within geographic units can have important consequences. You can select the independent or predictor variables based on the information available from previous research in the area. You should also use your knowledge of the problem here. In addition to independence between the variables, the samples themselves are considered to be independent.
Discriminant analysis is a valuable tool in statistics. It has gained widespread popularity in areas from marketing to finance. Discriminant analysis, just as the name suggests, is a way to discriminate or classify the outcomes. D.The pattern of loadings stays the same and the total variance explained by the factors changes also.
It can be utilized to assess the strength of the relationship between variables and for modeling the future relationship between them. This can be used to project the features of higher dimensional space into lower-dimensional space in order to reduce resources and dimensional costs. Logistic regression outperforms linear discriminant analysis only when the underlying assumptions, such as the normal distribution of the variables and equal variance of the variables do not hold. A system for determining membership in a group may be constructed using discriminant analysis. The method comprises a discriminant function that is premised on linear combinations of the predictor variables that offer the best discrimination between the groups. If there are more than two groups, the model will consist of discriminant functions.
In this case, LDA fails to create a new axis that makes both the classes linearly separable. Fisher’s linear discriminant is used in statistics and other fields to find a linear combination of features that characterizes or differentiates atleast two classes of objects or events. Linear discriminant analysis is believed to be a generalization version of Fisher’s linear discriminant.
Such procedures differ in the assumptions made about the distribution of the variables in the population. If the variable is positive with low values and represents the repetition of the occurrence of an event, then count models like the Poisson regression or the negative binomial model may be used. LDA is closely related to analysis of variance and regression analysis, which also attempt to express one dependent variable as a linear combination of other features or measurements.
Regression Coefficient
In various fields of application, different terminologies are used in place of dependent and independent variables. Thus, canonical correlation analysis is multivariate the regression equation in discriminant analysis is called the linear regression deepened into latent structure of relationship between the DVs and IVs. Discriminant analysis is a particular case of canonical correlation analysis .
- The direct method involves estimating the discriminant function so that all the predictors are assessed simultaneously.
- Before we move into the details of the subject right here, it is important to get the basics right.
- For ordinal variables with more than two values, there are the ordered logit and ordered probit models.
Linear regression shows the linear relationship between the independent variable (X-axis) and the dependent variable (Y-axis), hence called linear regression. The dependent variable is categorical i.e. it can take only integral values representing different classes. The probabilities describing the possible outcomes of a query point are modelled using a logistic function.
The purpose of this answer is to explain the exact mathematical relationship between linear discriminant analysis and multivariate linear regression . It will turn out that the correct framework is provided by reduced rank regression . Python and R are both powerful coding languages that have become popular for all types of financial modeling, including regression. These techniques form a core part of data science and machine learning where models are trained to detect these relationships in data. In multiple regression, the coefficient of multiple determination indicates the percentage of the variation in Y that can be explained by all independent variables. In a regression equation, the beta coefficients indicate the effect on the dependent variable of a 1-unit increase in any of the independent variables.
Discriminant Function
Next, we see the inherent dimension reduction in this method and how it leads to the reduced-rank LDA. After that, we see how Fisher masterfully arrived at the same algorithm, without assuming anything on the data. A hand-written digits classification problem is used to illustrate the performance of the LDA. The merits and disadvantages of the method are summarized in the end. Limited dependent variables, which are response variables that are categorical variables or are variables constrained to fall only in a certain range, often arise in econometrics. Once a regression model has been constructed, it may be important to confirm the goodness of fit of the model and the statistical significance of the estimated parameters.
If you have many classes and not so many sample points, this can be a problem. There is a well-known algorithm called the Naive Bayes algorithm. Here the basic assumption is that all the variables are independent given the class label. Therefore, to estimate the class density, you can separately estimate the density for every dimension and then multiply them to get the joint density.
Discriminant functions
The dashed or dotted line is the boundary obtained by linear regression of an indicator matrix. In this case, the results of the two different linear boundaries are very close. The maximum number of discriminant functions will equal the number of predictor variables or the number of group categories minus one – whichever is smaller. Discriminant analysis is statistical technique used to classify observations into non-overlapping groups, based on scores on one or more quantitative predictor variables. Discriminant analysis is used when groups are known a priori .
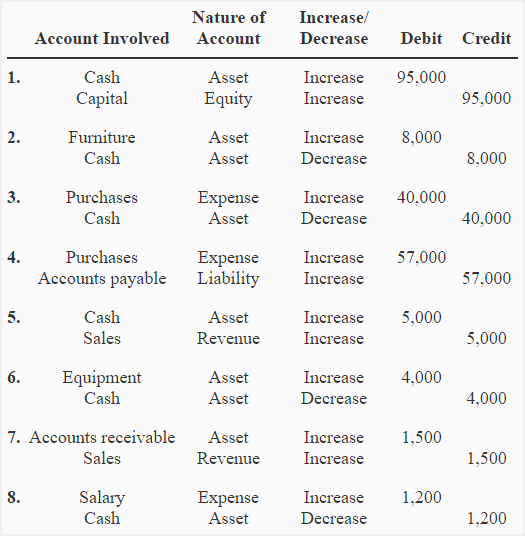
Table 1. Example data.
With developments and improvements in the techniques in discriminant analysis, it has been adapted into a form that can provide solutions to modern-day problems. Since the loans given to corporations are always for a large amount, discriminant analysis is essential to ensure that the bank is always making informed decisions. An example of discriminant analysis is using the performance indicators of a machine to predict whether it is in a good or a bad condition. The object category is unknown while doing cluster analysis. The object category is already established before beginning discriminant analysis.